Go to the previous, next section.
This chapter is addressed to the ILU developer who wants to add support for a new programming language to ILU.
Supporting a new programming language for ILU involves four tasks: (1) defining how ISL is mapped into that programming language; (2) designing how stubs work, and their interface to the Language-Specific Runtime (LSR) support; (3) writing the stub generator (stubber) for that language; and (4) writing the Language-Specific Runtime (LSR) support. Naturally the existing language supports provide interesting examples when defining a new one. The best existing supports are currently those for C and Python. Understanding of the other generic parts of this reference manual is assumed.
Adapting ILU to work on different operating system interfaces is an independent topic, that of porting (not addressed in this chapter).
The problem here is to define how each of the concepts in ISL maps into a concept in the programming language. We prefer to map into the most natural presentation for the language at hand. For example, a SEQUENCE OF SHORT CHARACTER maps into a C char *, because char * is by far the most conventional way to represent a string in C, even though no tasteful person would make that choice if starting from scratch today.
When working on a language L for which the OMG has defined a CORBA mapping, we strive to satisfy the following equation:
for all acceptable IDL i: ISL-to-L(IDL-to-ISL(i)) = IDL-to-L(i)where IDL-to-L is the mapping defined by CORBA, IDL-to-ISL is our standard way of translating CORBA interfaces into ILU interfaces, acceptable IDL is IDL that's acceptable to our IDL-to-ISL translation, and ISL-to-L is the mapping being defined [hmm, this equation should probably be a little more complicated, to take into account the fact that one IDL source can declare multiple "interfaces"]. If there is no ISL-to-L that satisfies the above equation, we also have to modify IDL-to-ISL (and thus all the other ILU language mappings too -- so we don't want to do this very often!).
When working on a language for which there is a defined IDL mapping, it's also necessary to have a mapping for the standard CORBA "psuedo-objects", and the methods of CORBA::Object. Even when working without interference from CORBA, it's worth considering the issues those features address. ILU does not (and thus your language mapping need not) attempt to provide the following parts of CORBA: Interface Repository, Implementation Repository, Dynamic Invocation Interface, Dynamic Server Interface, Basic Object Adaptor, Portable Object Adaptor (yet).
ILU also has some general (i.e., not explicitly appearing in any particular ISL file) features that CORBA doesn't and must be addressed in a language mapping; prominent among them are servers, and their attendant ports and object tables. You will need to define how servers are created and shut down; this should be able to follow the spirit of the kernel interface on this matter closely. Define how an application indicates which of its true objects are in which of its true servers. You may want to provide a "default server" for use in simple programs that don't want to explicitly manage multiple servers. ILU also involves explicit management of ports, to give applications control over selection of RPC and transport protocols used; define how ports are created and destroyed. ILU supports (but not as completely as we'd like) the possibility of multiple ports on a server, with inclusion of information about all those ports in an object reference (string binding handle, "SBH", in ILU parlance; see section String Binding Handle). Define how an application supplies an object table to a server.
ILU's has its own security story. This story only concerns how to provide authentication, message integrity, and message secrecy -- or a selected subset of them. The paradigm is that a security filter can appear in the protocol stack; higher layers need only concern themselves with getting the necessary parameters to and from that security filter. The necessary parameters are bundled into an ilu_Passport, which is a collection of ilu_IdentityInfos. Each call may optionally have an ilu_Passport associated with it. You design the language-specific appearance of passports and identities, and a calling convention that incorporates implicit optional parameters.
There are two more implicit optional parameters, and they are of interest only on the client side of a call: a serialization guarantee instance (ilu_Serializer) and an pipeline (ilu_Pipeline). You design the language-specific appearance of serialization guarantee instances and pipelines, and further use of the calling convention that incorporates implicit optional parameters.
A language mapping should preserve the type structure of the ISL. In particular, the subtyping relationships should be preserved. That is, if ISL type T1 is, according to ISL semantics, a subtype of ISL type T2, then LT1 (the language-L mapping of T1) should be, according to language L's semantics, a subtype of LT2.
The biggest part of this definitional challenge usually concerns objects. Many programming languages do not have an object system as rich as ISL's; some have no object system at all. If not already present, an object system of sufficient richness must be invented and embedded in the programming language. C is one example of this: it has no object system at all, and so the OMG invented an embedded one for use with CORBA. Modula-3 is an even thornier example: it has an object system, but with only single inheritance; for an ILU mapping, a multiple-inheritance object system has to be embedded in Modula-3 -- in the least annoying way possible (and exactly what is least annoying is unfortunately debatable).
Another major part of the defintion to be made concerns storage management (and for objects, management of other, hidden, resources). Prominent areas where this issue shows up are in management of objects, and of arguments, results, and exception parameters of method invocations. Servers and the call-specific meta-objects (passports, identities, pipelines, and serialization guarantee instances) also need management. In the simplest case, you map into a language that is defined to include a garbage collector, and do not aspire to enable the programmer to free resources before the collector eventually does. However, even when a garbage collector is available, some application programmers may demand to be able to release the resources hidden behind an object (e.g., private state, file handles, ILU kernel objects) when the application detects that it's done with the object, which (for most collectors) can be arbitrarily long before the collector does. When a garbage collector is not available, or when explicit management by the application is desired, a reference-counting scheme -- or something even more painful -- is often employed. Some languages are not defined to include a garbage collector, but add-on collectors are available; for such a language, the most flexible design would cope with operation both with and without a collector.
Another issue that must be addressed in defining a language mapping (and even more so in the following steps) is control structure. ILU is designed to be usable in both single-threaded and multie-threaded environments. Some languages are defined to be one or the other. Other languages (such as C and C++) are single-threaded "by default", but can be used to write code for use in a multi-threaded environment. Your mapping should support the same choices in this area as the language does.
In a single-threaded environment, many packages use a "main loop" that does "event dispatching" as their top-level control structure. ILU is such a package, on the server side. Unfortunately, some programs must integrate two or more such packages -- and are thus presented with a problem: there can't be two or more *top-level* control structures. Solving this problem requires cooperation from the main-loop-using packages involved. The solution involves picking one package's one main loop (or inventing a completely independent loop) to be the top-level control, and making the other packages "adopt" the chosen main loop for their own use. ILU is designed to be able to play either role: that of "donating" or "adopting" main loop services; your language mapping (for a single-threaded language) should expose the support for both roles.
In a multi-threaded environment, there are issues of synchronization between threads. At the language mapping level, these are mostly independent of what you must define. Just follow this simple rule: ILU objects and their methods allow just as much concurrency as the other objects and methods in the language. Of course, the implementations of ILU objects will involve synchronization issues, but that's a subject for later sections. The one place where synchronization typically shows up in a mapping defintion is in object tables, whose methods are called under certain mutual exclusion conditions.
See section Threads and Event Loops and the "Locking" section of `iluxport.h' for more details on mutexes and locking comments.
Your language mapping must include locking comments in the defined interfaces (e.g., the definition of an object table, and interfaces emitted by the stubber). One or the other of the above views (invariant-oriented or object locking) must be complete; both would be nice.
ILU PICKLEPICKLEBOOLEANREAL
The PICKLE(<type-id>, <marshalled-value>),
where the <type-id> identifies the value's type, and the <marshalled-value>
is a representation of the value in some standard form. In ILU, we use the
standard ILU type id (or CORBA repository id) for the <type-id>,
and the standard representation form is a simple big-endian, non-aligned form. The tuple
itself is bundled up into a sequence of bytes, for more convenient handling in the ILU
kernel and with the various wire protocols.
The language runtime should provide general compatibility with CORBA's notion
of any, which is another dynamically typed value type. This basically means that
there should be two kinds of objects added to those supported by the language runtime:
Any and Typecode. The Any object is used as the language-specific
representation of an ILU pickle; the Typecode object is used to represent an ISL
type.
The Any object LSR support is quite simple. It should be implemented as an opaque object with accessors. This allows the value contained in the Any to be kept in the pickle form until it is asked for, which makes the operation of ILU pickles particularly efficient in services such as name services or event services, in which the values are never unpickled. There should be a constructor function for Any which allows an instance to be constructed from a Typecode and a language-specific value. There are minimally two methods on the Any object, one to retrieve the Typecode of the contained value, and one to retrieve the contained value itself in language-specific form. It is allowable to refuse to return a language-specific value if the Any contains a pickled value the type ID of which is unknown to the language runtime.
LSR Typecode support is also simple. There should be a method to retrieve the type ID
of the Typecode, and another to compare two Typecode values for equality. Typecode
values are typically generated by the stubber, one for each type defined in an interface's
ISL. The language runtime must also provide Typecode values for the
ILU basic types, such as REAL or BYTE. To aid in that, the kernel
exports a set of character arrays containing the type ID's for those basic types; see
the file `ILUSRC/runtime/kernel/ilutypes.h' for the names of these
arrays.
This task mainly involves designing what the generated stubs look like, prominently including: the data structures that represent ILU objects, the way the storage management issues are implemented, and the sequence of LSR calls involved in making and serving ILU method calls. For the first two, see section Object Management for a discussion of the options. We have found the last one to be facilitated by writing some example stubs by hand, and writing down a draft LSR interface. A pre-requisite to doing these tasks is understanding how the ILU runtime kernel is designed to support LSRs (which is discussed in the section on writing the LSR).
Another issue to address in runtime design is how the control structure options defined in the language mapping are implemented, and the impact on the rest of the runtime design.
It is important to understand the major pieces of a running ILU program. At the base, there is some operating system interface, and libc (the standard ANSI C runtime library). On top of the OS and libc is the ILU runtime kernel, a common piece of runtime support. It is written in ANSI C, used in each of ILU's language runtime supports, and does as much of that job as possible. The remainder of the job is done by the LSR, which is just a thin (as thin as possible, but no more) veneer over the kernel. When multiple languages can co-exist in one runtime environment, their ILU LSRs should also be able to co-exist; the kernel is prepared to deal with multiple LSRs.
Each stub generator is an independent program, and can (in principle) be structured in any way, and written in any language. Most of the existing stubbers are written in ANSI C.
A more automated approach to stub generation, used to create the revised CORBA-compatible c++ stubber, has been introduced as of this writing (Sept. 1999). The tools for using this approach are found in `stubbers/genstub' and documented in the `stubbers/genstub/README.GRAMMAR' and `stubbers/genstub/README.USAGE'. Using the genstub approach, the bulk of the code generation is specified in a generation grammar specifically designed for stubbing, in which the leaves of the generation trees are multi-line literal blocks with symbolic substitutions.
Stubbers generally make use of a common interface definition parser (found in `stubbers/parser/') to translate interface definitions to a common internal form. The parser is based on a BISON grammar (in `ilu.bison', translated to `iluparse.c'); this file also includes some procedures of common utility to back-ends. The interface to the resulting common internal structure and to common utilities is defined in `iluptype.h'.
Much could be written about `iluptype.h', but right now I'll give only a few clues. First, it could profit from significant revision; sorry about that.
The type Procedure refers to a method of an object type. The type Class refers to an object type (ILU is full of places where "class" is used instead of "object type" -- because the word "class" was erroneously used for "object type" early in the project).
The type Type is confusing in many ways. The type Type refers to an occurence of a type reference in the parse tree -- not the underlying, analyzed type. Analyzed type information is found in a TypeDescription, which is hung off the Type appearing in the definition statement (TYPE name = ...;) that introduces that type information. For other Types, the supertype member (grossly misnamed) points toward another Type closer to the one that holds the TypeDescription. Type Type has two members that identify interfaces: one (Interface interface) identifies the interface in which the type reference appears; the other (string importInterfaceName) identifies the interface into which the reference is referring (i.e., the Ifc part of a type reference that looks like Ifc.Foo).
A good example might be the Python stubber, which is highly organized and clean.
This is about writing the veneer between (a) the kernel and (b) the stubs and application. Some of this topic is addressed in the refman, and some in the kernel's interface (`runtime/kernel/iluxport.h').
By default, the kernel operates single-threaded, using ILU's default main loop. If your language is multi-threaded, your LSR will need to make calls at startup time to switch the kernel into multi-threaded operation. If your language is single-threaded, your adopt-a-foreign-main-loop operation will need to call into the kernel to make it adopt a new main loop (you'll have to provide a "glue" object that translates between the ANSI C declaration of a main loop meta-object in the kernel interface and the language L declaration in your runtime interface). See section Threads and Event Loops for more details.
To switch the kernel to multi-threaded operation, four procedure calls must be made early in the initialization sequence. The procedures to be called are: ilu_SetWaitTech, ilu_SetMainLoop, ilu_SetLockTech, and ilu_NewConnectionGetterForked. See `iluxport.h' for details, and the Java and Common Lisp LSRs (found in `ILUSRC/runtime/java/' and `ILUSRC/runtime/lisp/') for usage examples.
Instead of the first three procedures, an LSR may call ilu_InitializeOSThreading to use predefined metaobjects constructed from the POSIX, Solaris 2, or Win32 threads API. This option is only available if running on a system that exports one of the above threads APIs, and only if --enable-os-threads was selected during the configuration step of installing ILU (see section Configuration Options).
See the "Concurrent I/O routines" section of `iluxport.h' for more details on this issue: how the kernel donates and adopts main loop services and FD waiting services.
Remember to rigorously document the use of mutexes in your internal interfaces and code. Verify it meshes properly with the locking comments in the kernel's interface.
This should be well documented in the "Client side routines" and "Server side" sections of `iluxport.h'.
For each language L, kernel object ko, and corresponding language-L lso, the object's server includes this invariant: either (a) ko and lso both exist and point to each other, or (b) neither points to the other (and either or both may have been freed). This organizes the relationship between the two objects, which otherwise could be created and destroyed rather independently (with ensuing confusion in any code that must relate the two). More details are in the "Deleting Objects" section of `iluxport.h'.
An ILU object is represented in a program instance (aka running program, UNIX process) by a kernel object (KO) and, for every programming language X in which that object is being manipualted, an Application-level Language-Specific Object (App LSO for language X). The X App LSO is an object in the object system of the ILU mapping to X. In fact, there may be multiple X App LSOs corresponding to one ILU object -- when CORBA::Object::duplicate isn't a no-op. Between an App LSO and its KO there may be a number of auxiliary objects that implement the defined relationship between the two main objects; like the KO, these auxiliary objects are not exposed to the application.
Both the KO and the X App LSO (or one of its associated auxiliary objects) have slots that hold pointers to the other (or NIL). The KO's slot that holds a pointer to the X LSO is accessed via getter and setter procedures in the kernel interface, ilu_GetLSOilu_SetLSO
The ILU runtime for language X can be designed such that X App LSOs are managed by a garbage collector, or such that they are explicitly managed by the application -- or even to leave that choice up to the application. The KOs are explicitly managed by the kernel and LSRs. A KO will persist as long as it has any associated LSOs -- or any of certain other reasons (which are private to the kernel) to persist. One of those other reasons is being of a collectible MST and having recently had live surrogates. The LSR's role in the explicit management of a KO is captured in its calls on ilu_SetLSOilu_SetLSO
KO and App LSO can exist and be used independently of one another -- for uses that don't logically require both. For example, an application can create App LSOs and use them only locally -- and as long as there's no attempt to marshal or unmarshal the LSO (or do any other ILU-specific thing with it), there will be no KO or auxiliary objects involved. And of course you would expect that in a multi-language runtime environment, the existence of a KO and X App LSO does not require the existence of a Y App LSO. The kernel can serve and make built-in calls using only the KO. In special times during the startup and shutdown sequences of objects, you might also expect an KO to exist while there is no corresponding App LSO.
In some cases, a dissociated KO and X App LSO can be found and linked together by the ILU X runtime; sometimes this can even involve creating one of those two when starting from the other. The cases depend on whether we're talking about a true or surrogate object, and, in the true object case, whether the object's server has an object table.
The ILU X runtime should be able to create from scratch a surrogate App LSO for any given ILU object type that has been registered (by a stub) with that runtime. In general we expect the aforementioned registration step to supply a procedure for instantiating a new App LSO of the appropriate language type; in a language with sufficiently powerful reflective capabilities, the runtime can do the instantiation without calling type-specific code.
The ILU X runtime is not expected to be able to create a true App LSO; only the application is expected to be able to do that. The application can always create App LSOs on its own initiative. Additionally, if the application supplies an `object table' to the server, the ILU kernel and X runtime can call on this object table to create App LSOs when needed. Remember that the object table that the application supplies will create true App LSOs, while the object table of the kernel server must return KOs (that are true for the server's language).
The kernel is able to create a KO given an SBH, or (equivalently) an instance handle and a server. At the kernel interface, this ability is bundled into procedures that either find an existing KO or create a new one. For creating a KO that is true for some language, there are two cases: (1) the caller wants the kernel to consult the server's object table (if any), and (2) not. Case (2) is useful when the ILU X runtime is already holding the App LSO, and just wants the corresponding KO; case (1) is useful when starting from just the SBH. Case (1) is ilu_ObjectOfSBHilu_FindOrCreateTrueObjectilu_FindOrCreateSurrogate
An App LSO should be able to identify the SBH, or the instance handle and server, of the ILU object in question. There are any number of ways of formulating this. It is most interesting for true objects, because this is a question of how this responsibility is put upon the application. In the C mapping, the procedure for creating a true App LSO takes instance handle and server as arguments. In the Modula-3 mapping (now defunct), the App LSO had to implement a "get-server" method, and the server's M3 object table has an additional "instance-handle-from-object" method (a default implementation being used for servers that lack object tables).
There must be some way to determine when an application is done with the App LSO(s) of a given ILU object. In some languages, a garbage collector is available to do this. To be useful, it must be possible to register a `finalization' procedure that can be run after the collector determines an object is unreachable. If this is not possible, garbage collection cannot be used to manage App LSOs. Furthermore, there must be a `WeakRef' facility. A WeakRef is a thing that holds a disguised pointer (i.e., one that doesn't count as keeping its target `reachable') to some object; there is a `reveal' operation on the WeakRef that returns a normal pointer to the obscurely-referenced object. If and when the collector decides the obscurely-referenced object is unreachable, it atomically changes the WeakRef such that future invocations of `reveal' will return NIL.
In languages without a useful garbage collector, some other method must be used to determine when an App LSO is no longer useful to the application. The CORBA-mandated solution is the most useful one. It can be understood as reference counting. The App LSO (or one of its auxiliary objects) holds a reference count. Every unmarshalling of the object increments the count. CORBA::Object::duplicate is used to produce an independently managed reference from some existing reference; this procedure increments the reference count and returns the given reference. CORBA::Object::release is used to declare the application done with (a copy of) the reference; it decrements the count. When the reference count reaches 0, all parts of the application are done with the App LSO.
Following is a summary of the life-cycle of a KO and App LSO (and the linkage between them).
One startup path begins with the application creating a true App LSO. This may be on the application's initiative, or as the result of an object table invocation. Creation of the App LSO does not by itself require creation of the KO or any linkage between them; the application can now do arbitrary non-ILU things with the App LSO. At some future point the X LSR may need to get the corresponding KO. If the KO and App LSO are already extant and cross-linked, the pointer from App LSO to KO reveals this, and the LSR is done. Otherwise, the kernel is consulted, via ilu_FindOrCreateTrueObject
Let us digress a moment to think carefully about object tables. The API for ILU's X mapping includes a declaration of the type of object tables; such an object table has an `instance-handle-to-object' method that returns an X App LSO. The implementation of this method is nearly arbitrary application code (the restriction is that it must run inside the server's mutex). The kernel interface uses a different type of object table, one whose `instance-handle-to-object' method returns a KO. This object table is implemented by the LSR, in terms of the application-supplied object table. The instance-handle-to-KO method first calls the instance-handle-to-App-LSO method, and then continues as outlined in the latter half of the previous paragraph, starting from where the LSR is holding an App LSO and wanting a KO.
Another startup path is unmarshalling an object. The LSR first calls a kernel routine (ilu_InputObjectIDilu_InputObjectID
Translating an SBH into an X App LSO proceeds much like unmarshalling; the difference is that the LSR starts by calling ilu_ObjectOfSBHilu_InputObjectID
Having considered the ways that KO and App LSO can be created and cross-linked, we now turn our attention to ways they can be dissociated (un-cross-linked) and destroyed.
The LSR may supply the application with an operation to explicitly dissociate the KO and App LSO. This leaves the KO to be destroyed by the kernel when the kernel has no other reason to keep the KO around, and the App LSO to be destroyed by the X language runtime (perhaps augmented by the X LSR with a reference counting scheme) when the application has no more need for it. However, we should also consider what happens if, at any time after this dissociation, the LSR finds itself again wanting to cross the bridge between the two objects. Starting from the App LSO, this is easy, because the kernel will gladly return the still-existing KO or create a new one (whichever is appropriate). Starting from the KO, consider whether the App LSO is true or surrogate. In the surrogate case, the LSR could easily instantiate a new App LSO. But the old one might still exist, and we would then have a violation of ILU's `EQ-ness preservation' property. Perhaps an application that explicitly dissociates KO and App LSO deserves what it gets in this case. If not, the LSR could keep its own instance-handle-to-App-LSO table (the LSR can arrange to know when the LSR is destroyed, and remove this table entry at that time), enabling the LSR to re-link the KO with the same old LSO if it still exists (and a new one otherwise). In the true case, the KO can be re-linked to an App LSO in the usual ways (by object table invocation or explicit true App LSO creation) and no others.
The other shutdown scenario starts with the LSR determining that the App LSO is no longer interesting to the application and no longer `very interesting' to the kernel (as revealed by the ilu_ObjectNoterilu_VeryInterested
The remainder of this document gives some worked examples.
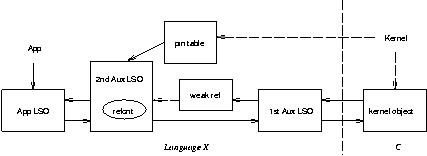
Here's a basic scheme for garbage-collected runtimes:
This is a very generic scheme, designed to minimize demands on the language runtime and application. Certain of the above objects can be coalesced when more demands can be made (we'll get explicit about this later). The pointers to X objects are visible to the garbage collector (and thus might not be simple pointers). The pointers to C objects are C pointers; we assume that either (a) the garbage collector either doesn't manage the C heap, or (b) it manages the C heap and can follow C pointers.
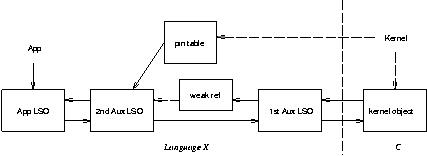
In this scheme ILU's language X runtime establishes finalization on the 2nd Auxiliary LSO; the 2A LSO is distinct from the App LSO exactly so that the Application can put its own finalization on the App LSO.
The 1A LSO could be coalesced with the WeakRef if the language doesn't require them to be distinct objects.
The 1A LSO could be merged into the 2A LSO (leaving the KO to point to the WeakRef, which in turn points obscurely to the 2A LSO) if either (a) an object can be made reachable again in its finalization procedure and then re-subjected to finalization (the 2A LSO will want two different finalizations, but the App LSO just one to run once, of course), or (b) fairly heaveyweight stuff can be done within a finalization procedure.
The pin table holds a pointer to the 2A LSO exactly when the kernel is `very interested' in the object; the LSR registers an ilu_ObjectNoter
Here's how the LSR gets an App LSO from an SBH. First, it calls the kernel's ilu_ObjectOfSBHilu_ObjectOfSBHilu_GetLanguageSpecificObjectilu_SetLSOilu_SetLSO
When the App LSO eventually becomes unreachable (from both the App and the pin table), the garbage collector should eventually schedule both the App LSO and the 2A LSO for finalization, setting the Weak Ref to NIL. If the X-Object-from-SBH procedure is executed after this point in time but before the finalization happens, the existing 1A LSO and Weak Ref will be traversed, to find the Weak Ref holding NIL, and a new 2A LSO and App LSO created if possible (as explained above). The finalization procedure puts the 1A LSO on a queue to be processed by an auxiliary thread or event handler. To avoid allocating in the finalization procedure, the queue is threaded through the 1A LSO. The auxiliary thread or event handler does the following for each 1A LSO it pulls from the queue. First, it establishes Inside(object's server's mutex, object's MST). Then it considers whether the auxiliary objects are the remnants of a forcible dissociation or the Weak Ref currently holds a NIL pointer. In either case, it is done; otherwise, it calls ilu_SetLSO
An App LSO can be forcibly dissociated from the kernel object. This involves entering the object's server's mutex and: setting the four pointers to/from the KO and App LSO to NIL; leaving the three pointers among the 1A LSO, 2A LSO, and WeakRef intact; and removing the LSO from the pin table. An application may want to do this as part of a graceful shutdown procedure. This leaves the App LSO fully extant and constructed as far as X code can tell, except that it's not linked into the ILU runtime.
When relying on a garbage collector, CORBA::Object::duplicate is the identity function, and CORBA::Object::release is a no-op.
An alternative is to not rely on a garbage collector, and require the application programmer to use CORBA::Object::duplicate and CORBA::Object::release to explicitly manage objects. The most straightforward approach is this:
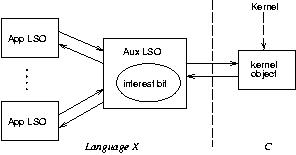
The `interest bit' records whether the kernel is `very interested' in this object. CORBA::Object::duplicate creates a new App LSO, as does each unmarshalling of the object. CORBA::Object::release deletes an App LSO -- both removing it from the set managed by the Aux LSO, and freeing it (what if true object?). When there are no App LSOs, and the interest bit is clear, the Aux LSO can be freed, and ilu_SetLSO
When multiple App LSOs are associated with a given abstract ILU object (i.e., kernel object), things get more interesting for true objects. We should not ask the application to implement cloning and consistency among clones. Instead, one of the App LSOs is true, and the others produced from it by CORBA::Object::duplicate or unmarshalling should be surrogates. ILU's language X stubber and runtime support should conspire to short-circuit calls made on a surrogate into calls on the true object, without involving the kernel. As far as the kernel is concerned, the Aux LSO is the true LSO. The short-circuiting could be done by structuring a client-side stub as follows: (1) am I a clone of the true object? (2) if so, call on the true object, otherwise (3) do the `normal' thing and call through the kernel.
If there is no state that needs to be associated with individual App LSO copies, we can instead use just one copy, with a reference count. That would look like this:
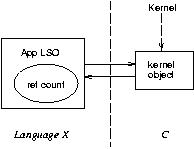
The kernel being `very interested' in the object contributes 1 to the reference count. CORBA::Object:duplicate, and each unmarshalling, increments the reference count (and returns the same LSO), while CORBA::Object::release decrements it. When the reference count goes to 0, CORBA::Object::release breaks the cross-pointers between the KO and the App LSO and then frees the App LSO.
To forcibly dissociate the KO and App LSO, just break the pointers between them.
To give the App the choice, independently for each abstract ILU object (i.e, each kernel object), of either: (a) letting the GC reclaim all App LSOs or (b) explicitly managing all App LSOs:
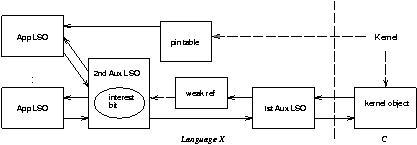
In this scheme we free the aux LSOs when either (a) the GC informs us that the 2A LSO is unreachable or (b) the last App LSO is deleted and the kernel is not `very interested' in the object. CORBA::Object::release destroys an App LSO. The pin table points to the true App LSO, if any.
Again, if we don't need distinct App LSOs, we can use one with reference counting:
This scheme requires the GC vs. explicit management choice to be made once per abstract ILU object.
To enable the choice independently at each App LSO:
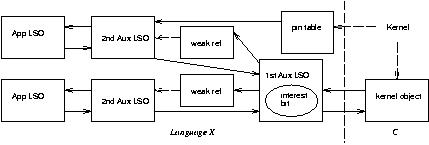
Here the LSR establishes finalization on each 2A LSO. The finalization, like CORBA::Object::release, removes the relevant WeakRef from the 1A LSO's set of WeakRefs. When that set is empty, and the kernel is not `very interested' in the object, the remaining LSO cruft can be freed, and ilu_SetLSO
Like objects, servers are also managed. However, their management is typically easier, because they are not first-class objects (i.e., can't appear in network interfaces) and so are manipulated in only a few ways. You will define a LSS (Language-Specific Server, the language mapping of an ilu_Server).
Each ilu_Server has a collection of LSSes associated with it,
in the same way that an ilu_Object has a collection of associated LSOs.
ilu_GetLSS and ilu_SetLSS manipulate the pointer from the ilu_Server
to its language-L LSS; the reverse pointer is your problem.
ilu_Servers are reference-counted, in a way similar to ilu_Objects. The server mutex invariant includes the assertion that, for each given language L an ilu_Server and it's L LSS point to each other, or neither does; each pointer from ilu_Server to LSS counts as a reference. Each locally-reified object in the server also counts as a reference.
The time when an ilu_Server is checked and possibly freed is when its mutex is exited. This should always be done by calling ilu_ExitServerMutex instead of fetching the mutex and applying the generic ilu_ExitMutex to it.
ilu_Pipelines and ilu_Serializers are managed by a simple, explicit reference counting scheme: you get a reference count of 1 when you create one, and may later release that reference count. Each ilu_Call that is associated with one of these metaobjects also counts as a reference, if ilu_StartCall succeeded and ilu_FinishCall hasn't yet been called.
ilu_Passports and ilu_IdentityInfos are managed by an even simpler scheme. ilu_DestroyPassport frees a ilu_Passport and those of its ilu_IdentityInfos that are marked as being owned by the ilu_Passport.
The kernel has a (partly deployed) standard way to return result codes and further details. It's called the "error system". `runtime/kernel/iluerror.h' describes the system in general terms, and `iluerrs.h' describes the particular types of errors currently possible. Most calls into the kernel take an error-signalling OUT parameter in the last position.
CORBA defines some standard system exceptions. An LSR must, when relaying an error from the kernel to an application, convert a kernel error into a CORBA standard system exception. To facilitate this, the kernel error system has been defined to include a collection of error types that correspond to CORBA's standard system exceptions.
Sadly, CORBA's standard collection of system exceptions doesn't correspond very directly to the full collection of all the things that can go wrong at the kernel interface. So there are some additional error types. Of course, when translating to a CORBA system exception, a standard one must be chosen. Also, there are some old error types left over from a previous version of the system; we are working on identifying which should be eliminated, and which should stay (perhaps with modification).
The kernel includes internal consistency checks, of two styles. When such a check fails, one of a few possible courses of action are taken. An application can specify what to do. Your mapping should expose this ability. See the "Internal Consistency Checking" section of `iluxport.h' for details.
The kernel is allowed to check consistency only with respect to conditions that it establishes itself; the kernel should not rely on correct operation of the LSRs or externally-supplied meta-objects (the error system should be used to report bogus behavior of other parties). An LSR may also do internal consistency checking, relying on correct operation of the kernel (and of course any meta-objects the LSR itself supplies); ilu_Check may be used for such checks.
ilu_DebugPrintf (see `iluxport.h') may be used to display messages to the user (if and when an LSR is in such dire straights that it needs to). Use this instead of printing directly to stderr to take advantage of the kernel's standard re-direction facility. See the "from debug.c" section of `iluxport.h'.
The kernel is loaded with conditional printf statements, for debugging purposes; an LSR may also include conditional printf statements using the same mechanism. See `runtime/kernel/iludebug.h', for the definition of the DEBUG macro and the particular bits available for control. The "from debug.c" section of `iluxport.h' also includes procedures that allow the control bits to be set; this should be exposed in your language mapping.
The ILU kernel uses a representation of time that has subsecond resolution. The exact resolution is dependent on the OS, and can be read from a global variable. See the "Time" section of `iluxport.h'.
The ILU kernel will restrain itself to use at most a given number of File Descriptors (FDs). See the "FD & Connection Management" section of `iluxport.h'. Your mapping should expose this control to applications.
It's not your job to integrate language L's runtime system with language M's. But supposing someone has, your LSR for L should be able to co-exist with the LSR for M. The kernel is prepared to deal with multiple LSRs. Each LSR should call ilu_RegisterLanguage, to get a ilu_LanguageIndex for use in certain kernel calls. To support 'Collectible' objects, an LSR normally calls ilu_SetGcClient, providing an object that can be 'pinged' to determine whether or not a process is still alive. In the case of multiple LSRs within one process, only one LSR should do this. An LSR can determine if a GC client has already been set by calling ilu_IsGcClientSet.
The stubs for an ISL interface are responsible for describing to the kernel each object type defined in that interface. The kernel will either make an internal copy of this information, or (if stubs for a different language have already described the type) check for equivalence of the given information with an already-existing internal copy. See the "Object Type Registry" section of `iluxport.h'.
Support for ANY introduces the need to describe all types defined in an interface. See ilutypes.h.
This is a simple bootstrap for solving the name service problem. It should be used to get to a real name service. See the "Simple Binding" and "from sbilu.c" sections of `iluxport.h'. Your mapping should expose this functionality.
ILU provides hooks for the following three security services: authentication, message integrity, and message secrecy. The services are provided by a transport filter that's written against the GSS API (see the section on RPC and transport protocols in the refman). This filter is parameterized by certain identity and credential information. [More needs to be written about these parameters and their management -- Bill?] See the "Identities and Passports" section of `iluxport.h'.
An ILU SBH (string binding handle; see section String Binding Handle) is organized like a WWW URL: a "scheme", followed by a colon and then some scheme-dependent stuff. The set of schemes understood by the kernel can be extended; see the "URL Syntax" section of `iluxport.h'.
The basic data structure the ILU kernel uses for pickles is ilu_Pickle,
which is a struct containing some allocated storage. The basic calls for input, output,
and sizing pickles are similar to those for other basic types:
extern void ilu_OutputPickle (ilu_Call, /* the call in progress */ ilu_Pickle, /* pointer to the pickled value */ ILU_ERRS((IoErrs)) *); extern ilu_cardinal ilu_SizeOfPickle (ilu_Call, /* the call in progress */ ilu_Pickle, /* pointer to the pickled value */ ILU_ERRS((IoErrs)) *); extern ilu_boolean /* the value read, PASS */ ilu_InputPickle (ilu_Call, /* the call in progress */ ilu_Pickle *, /* OUT: the value input, PASS */ ILU_ERRS((IoErrs)) *);
The ILU kernel exports a small set of functions to provide generic pickle support. They are intended to work with standard language-runtime functionality to provide language-specific pickle support. A pickle can be created via a function similar to this:
ilu_Pickle Pickle (ilu_string type_id, ilu_refany value)
{
ilu_Call_s call;
ilu_cardinal size;
ilu_Pickle pickle = { 0 };
ilu_Error err;
ilu_StartPickle (&call, &err);
if (ILU_ERRNOK(err)) return pickle;
size = <size-fn> (&call, value, &err);
if (ILU_ERRNOK(err)) return pickle;
ilu_WritePickle (&call, size, type_id, &err);
if (ILU_ERRNOK(err)) return pickle;
<output-fn> (&call, value, &err);
if (ILU_ERRNOK(err)) return pickle;
ilu_EndPickle (&call, &pickle, &err);
return pickle;
}
where <size-fn> is the normal function which calculates the marshalled
size of a value, and <output-fn> is the normal function which causes
the value of that type to be output. Of course, the example code must be re-written
in the target language instead of in C.
Similarly, a language-specific value may be extracted from a pickle with the analogue of this code:
ilu_string Unpickle (ilu_Pickle pickle, ilu_refany *value)
{
ilu_string type_id;
ilu_Error err;
<input-fn-type> <input-fn>;
type_id = ilu_PickleType (pickle, &err); /* read-only */
if (ILU_ERRNOK(err)) return ILU_NIL;
<input-fn> = <map-type-id-to-input-fn> (type_id);
if (input_fn == NULLFN) { /* this type unknown in this LSR */
ILU_CLER(*err);
*value = ILU_NIL;
return ILU_NIL;
} else {
ilu_Call_s call;
ilu_Pickle p2;
ilu_StartPickle (&call, &err);
if (ILU_ERRNOK(err)) return ILU_NIL;
if (!ilu_ReadPickle(&call, pickle, &err)) return ILU_NIL;
*value = <input-fn> (&call, &err);
if (ILU_ERRNOK(err)) return ILU_NIL;
ilu_EndPickle(&call, &p2, &err);
if (ILU_ERRNOK(*err)) {
if (*value != ILU_NIL)
<free-fn> (*value);
return ILU_NIL;
}
ILU_CLER(*err);
return type_id;
}
}
As before, the function <input-fn> is the normal language-specific
input function for the type designated by type_id, and <free-fn>
is the way of freeing an unused value. The value of type_id is read-only,
and only guaranteed to exist for the lifetime of the pickle. The function
<map-type-id-to-input-fn> must be provided by the language runtime;
it will usually need some support from the language stubber.
A non-obvious side
effect of calling ilu_ReadPickleilu_EndPickleilu_EndPickle
Finally, an ilu_Pickle value may be freed with a call to ilu_FreePickle.
See the file `ILUSRC/runtime/kernel/ilutypes.h' for more information on the kernel routines referred to here.
Generally, pickles are sent over a wire protocol as a simple sequence of bytes, which
consist of a prefix byte, a type ID, and the marshalled form of the value. However,
the CORBA IIOP requires a full description of the type to be sent,
rather than just the type ID. This makes using pickles with the IIOP much
more expensive than with other protocols, but must still be supported for CORBA
compliance.
To support this, the LSR must provide full type information to the
kernel for each constructed type in the ISL interface. The
LSR does this by calling type registration routines exported from the
ILU kernel. Typically, these calls are made by
stubber-generated interface initialization code. Some simple
constructed types may be registered with a single call: SEQUENCE,
OPTIONAL, ARRAY, OBJECT and alias types. Others (RECORD, UNION, ENUMERATION)
require a sequence
of calls. For example, a RECORD type is first registered by
calling ilu_RegisterRecordTypeilu_RegisterRecordFieldrecord type.
These calls should only be made if both VARIANT support and IIOP support are configured into the ILU system; the kernel will not export the required functions if one or the other is not available.
Go to the previous, next section.